Irgendwas mit Daten
KI, Marken, Analytics, Mediaplanung, DAM, PIM etc.
Ich mache etwas mit Daten
KI, Marken, Analytics, Mediaplanung, DAM, PIM etc.
Während der 90er war es ganz einfach: Harvest wurde konfiguriert, marschierte los und die Daten landeten in einer Datenbank – meist unstrukturiert. Aber es funktionierte leidlich. Jetzt – 20 oder 25 Jahre danach – ist das Leben nicht mehr ganz so einfach. Einerseits gibt es jetzt strukturierte Daten, es gibt diese schneller – mitunter sind sie bruchstückhafter. Aber ich greife vor. Seit ich Online Marketing mache, arbeite ich datenorientiert. An diese Daten komme ich am liebsten non-reaktiv, was bedeutet, dass diese erhoben werden, ohne Einfluss auf Nutzeraktivitäten zu nehmen. Web-Analytics ist ein Beispiel dafür. Gerade im E-Commerce werden jedoch weitaus mehr Informationen benötigt als die über das Nutzerverhalten auf den eigenen Websites. Es geht um Preismonitoring auf Online-Shops und Marktplätzen. Hersteller möchten wissen, wie gut Produkte bewertet werden und welches die Ursachen für schlechte Bewertungen sind. Es ist auch immer wieder spannend zu wissen, warum die eigenen Produkte schlecht ranken und die des Wettbewerbs gut – Fragestellungen der Suchmaschinenoptimierung. Hier geht es also nur um Fragen der Datenerhebung auf fremden Websites. Andere Verfahren, wie reaktive Marktforschung, werden nicht angesprochen – die Analyse der Daten ebenfalls nicht.
Es gibt spezialisierte Services, die beispielsweise beobachten, ob bestimmte Produkte auf ebay angeboten werden und zu welchem Preis. Diebischen Mitarbeitern kann man so auf die Spur kommen. Die Lage ist anders, wenn verschiedene Anbieter auf der gleichen Plattform bzw. dem gleichen Marktplatz einem ein spezifisches Produkt verkaufen wollen. Dann entscheidet der potenzielle Käufer meist nur anhand von zwei Kriterien – dem Preis und der Bewertung des Händlers. Es ist also wichtig zu wissen, welchen Preis der Wettbewerber haben möchte. Wenn es dann noch ein Werkzeug gibt, das eine algorithmische Entscheidung erlaubt, ist das eine große Erleichterung bei Fällen mit vielen Produkten. Für Amazon gibt es bereits eine große Zahl von Werkzeugen, mit denen entsprechende Aufgabenstellungen absolvierbar sind. Für andere Plattformen und Marktplätze ist die Werkzeugauswahl spärlicher. Wenn Sie beispielsweise bei Google nach Tools zum Preis-Monitoring suchen, werden Sie zunächst eine durchaus ansprechende Auswahl vorfinden. Sobald ihre Analysen ins Detail gehen, wird es weitaus schwieriger. Da gibt es Werkzeuge mit beträchtlichem Funktionsumfang – allerdings kann man damit nur die Preise auf zwei Hand voll Websites im Auge behalten. Andere Tools versprechen „Echtzeitanalysen“, die dann tatsächlich nur für wenige Produkte und nicht für alle Online-Shops funktionieren.
Grundsätzlich ist es aus meiner Sicht bei großen Unternehmen mit vielen Produkten, die dann auch noch in vielen Ländern aktiv sind durchaus sinnvoll, eine Stufe vorher einzusteigen und eine eigene Datenhaltung aufzubauen, um verschiedene Analysen selbst und genau auf eigene Fragestellungen durchführen zu können. Warum? Die meisten Toolanbieter führen die Datensammlung nicht selbst durch, sondern sie verlassen sich auf ein auf Crawling spezialisiertes Unternehmen. Die hierdurch gewonnen Daten werden in eigene Systeme integriert und hinsichtlich der Kundenanforderung aufbereitet. Das Crawling selbst zu übernehmen, ist mittlerweile eine durchaus anstrengende Aufgabe.
Nehmen wir ein leicht verständliches Beispiel aus einem etwas anders gelagerten Bereich, das Sie bitte nicht umsetzen sollen: Auf https://www.similarweb.com/ können Sie die Abrufzahlen vieler Websites der vergangenen drei Monate sehen. Wenn Sie bezahlen ist der Zeitraum länger. Auch wenn Sie zu viele Adressen auf einmal aufrufen, blockiert die Website. Können Sie jedoch über verschiede IP-Adressen und mit verschiedenen Browser-Ausprägungen zugreifen, dann funktioniert der Abruf ganz wunderbar. Jetzt wird es ein wenig technisch: Es wird ein Werkzeug benötigt, das verschiedene Browser in verschiedenen Netzbereichen vorspiegeln kann, um an die Daten zu gelangen. Natürlich will SimilarWeb dies verhindern – das hauseigene Geschäft muss geschützt werden. Wenn Sie sich nun vorstellen, dass Sie solche Verfahren bei einer großen Zahl von Websites anwenden möchten, die sich noch dazu in unregelmäßigen Abständen verändern, dass kann dies schon gewaltigen Aufwand verursachen. Und nicht, dass Sie sich durch mich inspiriert fühlen und bei SimilarWeb Daten klauen! Es ist nur ein Beispiel.
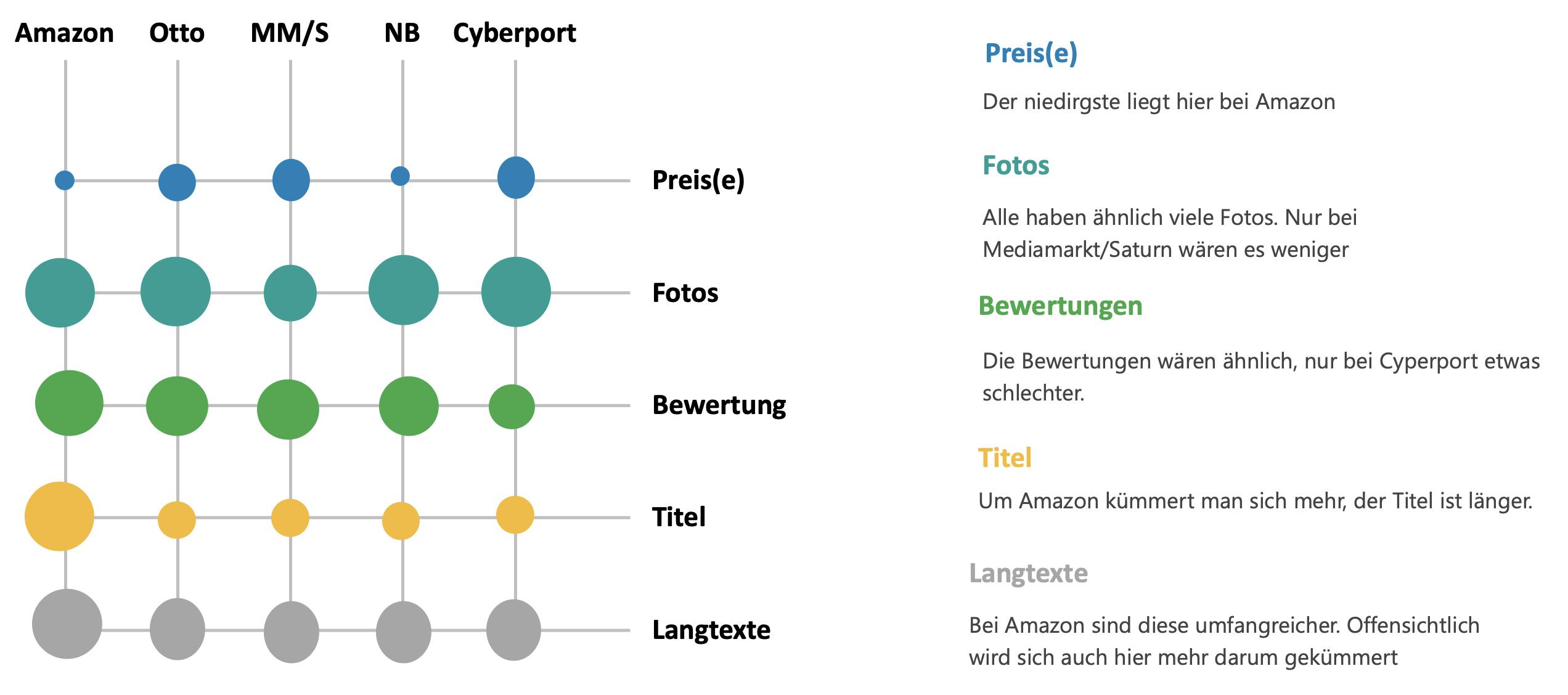
Was notwendig ist, sind Tools, mit deren Hilfe man den häufig in erkennbaren Strukturen vorliegenden Inhalt automatisiert erfasst. Vielleicht kennen Sie dies ja aus dem Amazon Marketing. Dort können Sie mit Amalytix feststellen, wie gut ihre Produktdaten auf Amazon sind. Wenn Sie über die entsprechenden Produktnummern ihrer Wettbewerber verfügen, können Sie auch diese Inhalte analysieren. Wäre es nicht toll, wenn Sie für ihre wichtigsten Keywords ihre und die Inhalte ihrer Wettbewerber auf allen für Sie wichtigen Online-Plattformen analysieren könnten? – Abgesehen davon, dass es den einen oder anderen Dienst gibt, der sich in diese Richtung bewegt – sofern sie nicht nur in Deutschland unterwegs sind und sofern Sie nicht nur die Kernmärkte interessieren, kann es lohnend sein, ein eigenes System zu entwickeln. Dann können Sie Preise beobachten und all die Inhalte analysieren, die für Sie Relevanz haben. Warum eigentlich? – Ich habe, einfach eine mehr oder weniger hypothetische Grafik gebaut, der Sie entnehmen können, wie die Produkte eines Unternehmens hinsichtlich verschiedener Dimensionen auf einigen Plattformen laufen. Wenn Sie sich nun vorstellen, dass diese Abbildung noch auf der Ebene unterschiedlicher Produktgruppen möglich wäre, dann erübrigen sich weitere Erläuterungen.
Beispielauswertung Product Data Crawling
Ich habe früher solche Aufgaben mit der import.io gelöst. Das geht noch immer, aber nur als Managed Service. Bei Diffbot ist das ähnlich. Nur dürfen Sie zwei Wochen testen. Möglicherweise wird Sie genau dieses Vorgehen wie auch mich davon abhalten, diese Wege zu gehen. Für einen MVP könnte es zu teuer werden. Auf der Suche nach einem angemessenen Werkzeug würden Sie vermutlich auch auf https://luminati.io/ stoßen. Nicht schlecht, das Ding. Aber ohne einiges von den Codes auf Websites zu verstehen, werden Sie ohne deren Managed Service auch nicht so einfach weiterkommen. Das Tool auf die Sachbearbeiter-Ebene zu legen und zu erwarten, dass Kollegen oder Kunden die Daten weiterer Websites selbständig erfassen können, wird nicht so leicht funktionieren. Diese drei Werkzeuge sind jedoch auf jeden Fall testenswert, wenn Sie sehr eigene Vorstellungen davon haben, was wie erfasst werden soll.
Es gibt aber noch einen anderen Weg: Ganz neu und nicht ganz fertig ist https://www.zyte.com/ Dort gibt es recht gute Möglichkeiten zum strukturierten Import von Produktinformationen sowie von Meldungen auf Nachrichtenseiten. Das ist viel umfangreicher als die Informationen, die man sonst von Diensten zum Preis-Monitoring bekommt, aber nicht ganz so individuell wie Arbeit mit den drei vorgenannten Produkten. Aus meiner Sicht ein gesunder Mittelweg und darüber hinaus sehr einfach bedienbar. Es ist lediglich notwendig, die URL einer Übersichtsseite einzugeben – das ist alles. Per JSON oder API sind die Daten in eigene Systeme importierbar und können dann nach eigenen Wünschen gespeichert und analysiert werden.